publications
Happy to be cited!
2026
-
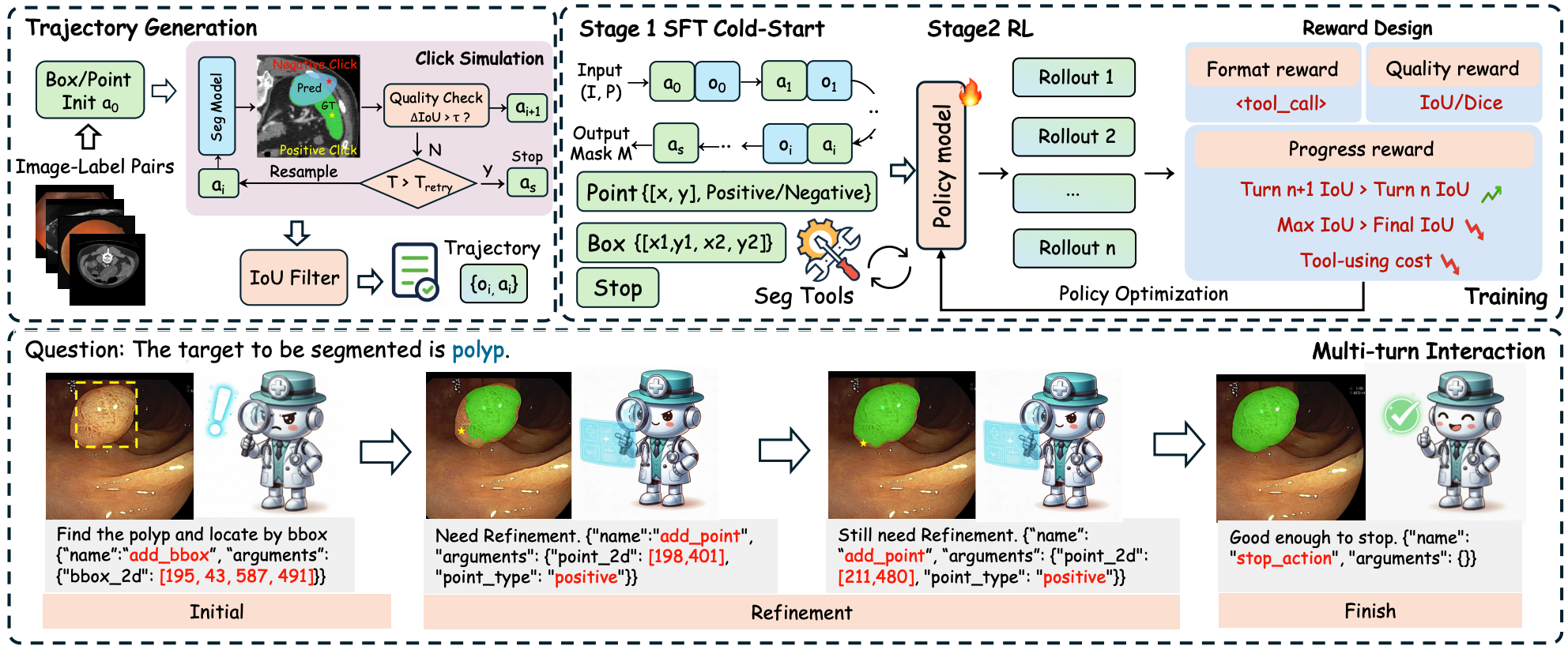 MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement LearningShengyuan Liu , Liuxin Bao , Qi Yang, and 6 more authors2026
MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement LearningShengyuan Liu , Liuxin Bao , Qi Yang, and 6 more authors2026We propose MedSAM-Agent, a framework that reformulates interactive segmentation as a multi-step autonomous decision-making process. We develop a two-stage training pipeline that integrates multi-turn, end-to-end outcome verification with a clinical-fidelity process reward design. Extensive experiments across 6 medical modalities and 21 datasets demonstrate state-of-the-art performance.
@misc{MedSAMAgent, title = {MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning}, author = {Liu, Shengyuan and Bao, Liuxin and Yang, Qi and Geng, Wanting and Zheng, Boyun and Li, Chenxin and Chen, Wenting and Peng, Houwen and Yuan, Yixuan}, year = {2026}, eprint = {2602.03320}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2602.03320}, } -
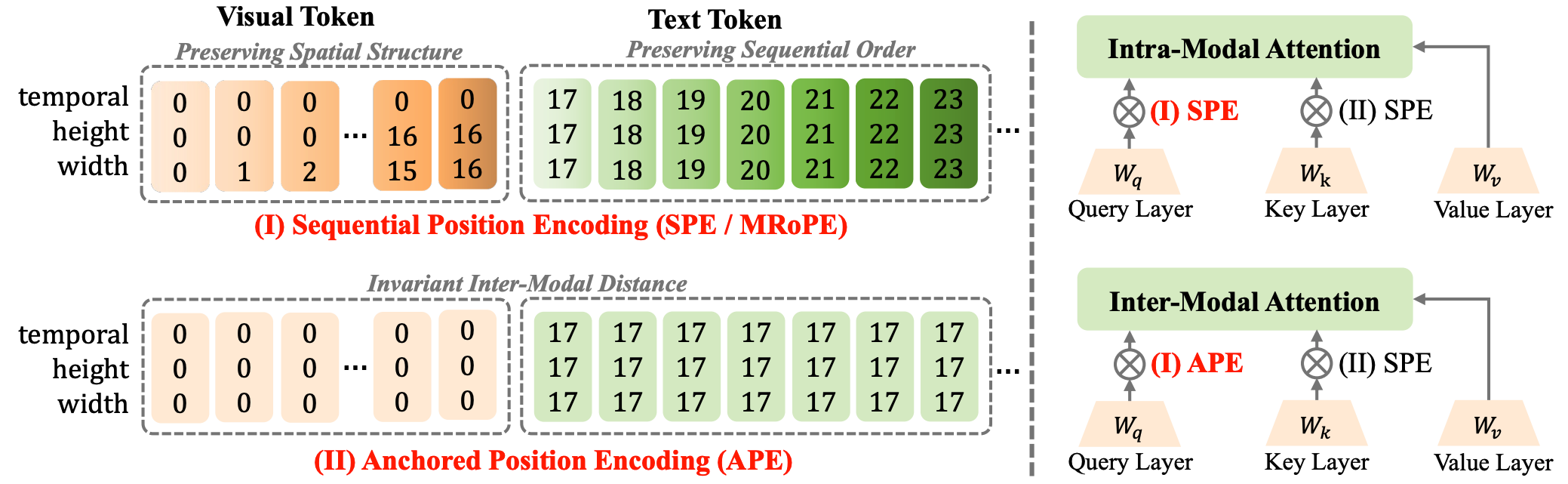 Beyond Sequential Distance: Inter-Modal Distance Invariant Position EncodingLin Chen, Bolin Ni , Qi Yang, and 5 more authors2026
Beyond Sequential Distance: Inter-Modal Distance Invariant Position EncodingLin Chen, Bolin Ni , Qi Yang, and 5 more authors2026We propose inter-modal Distance Invariant Position Encoding (DIPE) that disentangles position encoding based on modality interactions. DIPE retains the natural relative positioning for intra-modal interactions while enforcing anchored perceptual proximity for inter-modal interactions, effectively mitigating visual fading in long-context scenarios for Multimodal Large Language Models.
@misc{DIPE, title = {Beyond Sequential Distance: Inter-Modal Distance Invariant Position Encoding}, author = {Chen, Lin and Ni, Bolin and Yang, Qi and Wang, Zili and Ding, Kun and Wang, Ying and Peng, Houwen and Xiang, Shiming}, year = {2026}, eprint = {2603.10863}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2603.10863}, } -
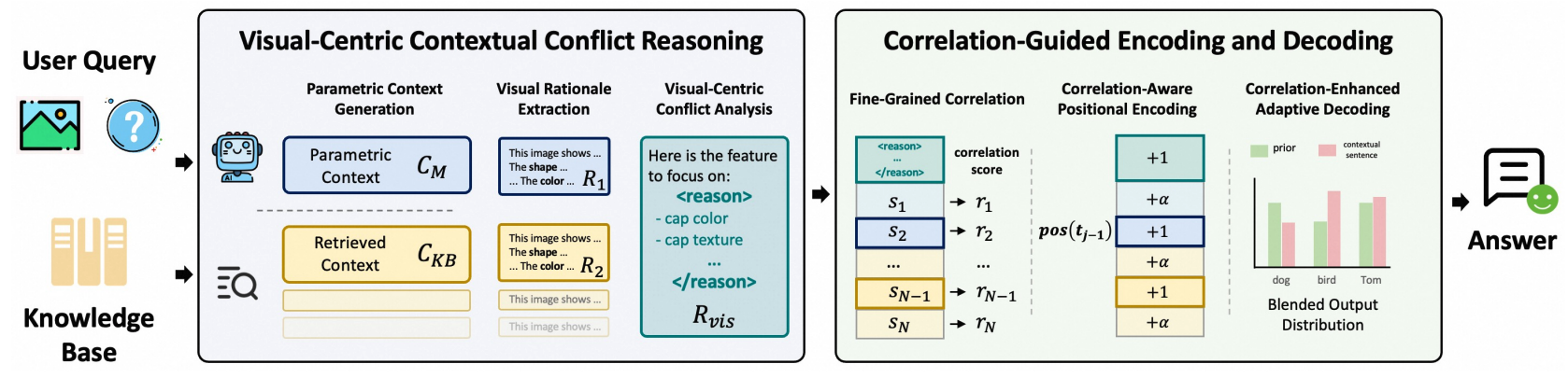 CC-VQA: Conflict-and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question AnsweringYuyang Hong, Jiaqi Gu , Yujin Lou , and 7 more authors2026
CC-VQA: Conflict-and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question AnsweringYuyang Hong, Jiaqi Gu , Yujin Lou , and 7 more authors2026We propose CC-VQA, a novel training-free, conflict- and correlation-aware method for knowledge-based VQA. Our method comprises Vision-Centric Contextual Conflict Reasoning and Correlation-Guided Encoding and Decoding. Extensive evaluations on E-VQA, InfoSeek, and OK-VQA benchmarks demonstrate state-of-the-art performance, yielding accuracy improvements of 3.3% to 6.4%.
@misc{CCVQA, title = {CC-VQA: Conflict-and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question Answering}, author = {Hong, Yuyang and Gu, Jiaqi and Lou, Yujin and Fan, Lubin and Yang, Qi and Wang, Ying and Ding, Kun and Wu, Yue and Xiang, Shiming and Ye, Jieping}, year = {2026}, eprint = {2602.23952}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2602.23952}, }



2025
-
 HunyuanOCR Technical ReportHunyuan Vision Team , Pengyuan Lyu , Xiang Wan , and 7 more authors2025
HunyuanOCR Technical ReportHunyuan Vision Team , Pengyuan Lyu , Xiang Wan , and 7 more authors2025This paper presents HunyuanOCR, a commercial-grade, open-source, and lightweight (1B parameters) Vision-Language Model dedicated to OCR tasks. HunyuanOCR demonstrates superior performance, outperforming commercial APIs, traditional pipelines, and larger models, securing first place in the ICDAR 2025 DIMT Challenge (Small Model Track).
@misc{HunyuanOCR, title = {HunyuanOCR Technical Report}, author = {Team, Hunyuan Vision and Lyu, Pengyuan and Wan, Xiang and Li, Guanwei and Peng, Shihui and Wang, Weijin and Wu, Lulu and Shen, Huilin and Zhou, Yi and others}, year = {2025}, eprint = {2511.19575}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2511.19575}, } -
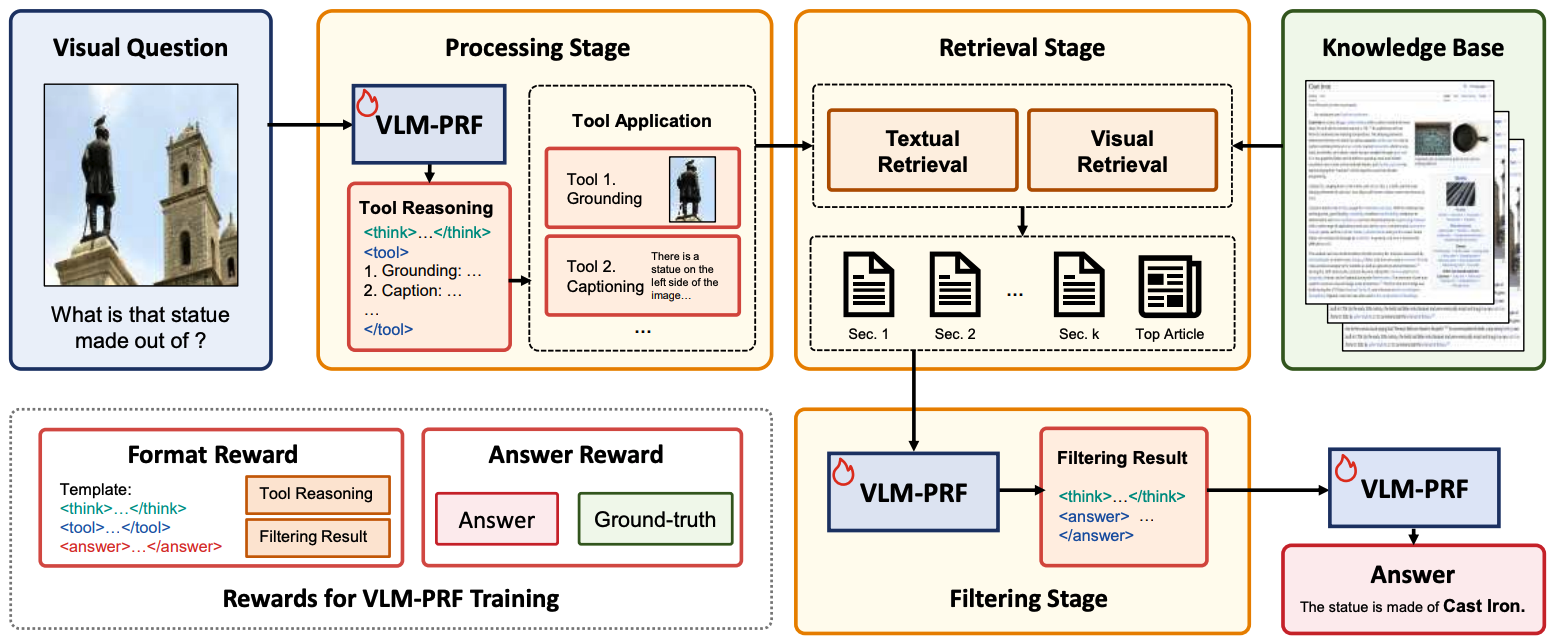 Knowledge-based Visual Question Answer with Multimodal Processing, Retrieval and FilteringYuyang Hong, Jiaqi Gu , Qi Yang, and 6 more authors2025
Knowledge-based Visual Question Answer with Multimodal Processing, Retrieval and FilteringYuyang Hong, Jiaqi Gu , Qi Yang, and 6 more authors2025We propose Wiki-PRF, a three-stage method for knowledge-based visual question answering including Processing, Retrieval and Filtering stages. We introduce a visual language model trained with answer accuracy and format consistency as reward signals via reinforcement learning. Experiments on benchmark datasets (E-VQA and InfoSeek) show significant improvements, achieving state-of-the-art performance.
@misc{WikiPRF, title = {Knowledge-based Visual Question Answer with Multimodal Processing, Retrieval and Filtering}, author = {Hong, Yuyang and Gu, Jiaqi and Yang, Qi and Fan, Lubin and Wu, Yue and Wang, Ying and Ding, Kun and Xiang, Shiming and Ye, Jieping}, year = {2025}, eprint = {2510.14605}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2510.14605}, } -
 R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce LearningQi Yang, Bolin Ni , Shiming Xiang, and 3 more authors2025
R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce LearningQi Yang, Bolin Ni , Shiming Xiang, and 3 more authors2025We propose R-4B, an auto-thinking MLLM that adaptively decides when to think based on problem complexity. The central idea is to empower the model with both thinking and non-thinking capabilities using bi-mode annealing, and apply Bi-mode Policy Optimization (BPO). Experimental results show that R-4B achieves state-of-the-art performance across 25 challenging benchmarks, outperforming Qwen2.5-VL-7B in most tasks.
@misc{R4B, title = {R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning}, author = {Yang, Qi and Ni, Bolin and Xiang, Shiming and Hu, Han and Peng, Houwen and Jiang, Jie}, year = {2025}, eprint = {2508.21113}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2508.21113}, } -
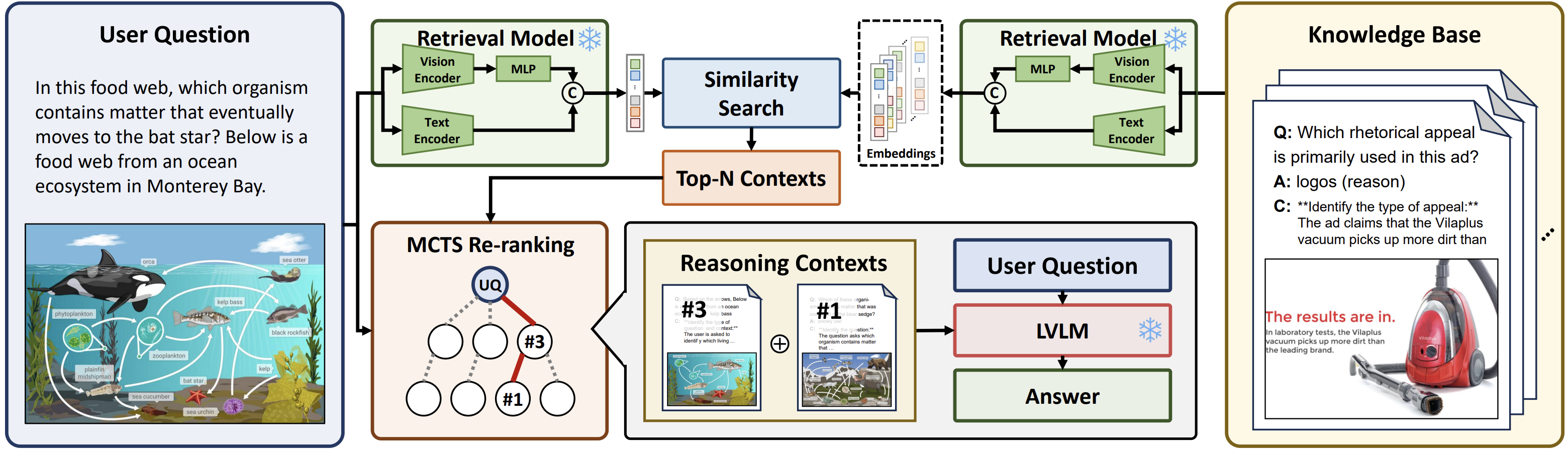 Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models StrongerQi Yang, Chenghao Zhang , Lubin Fan , and 3 more authors2025
Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models StrongerQi Yang, Chenghao Zhang , Lubin Fan , and 3 more authors2025We propose a multimodal RAG framework, termed RCTS, which enhances LVLMs by constructing a Reasoning Context-enriched knowledge base and a Tree Search re-ranking method. We introduce a self-consistent evaluation mechanism and Monte Carlo Tree Search with Heuristic Rewards (MCTS-HR). Extensive experiments demonstrate state-of-the-art performance on multiple VQA datasets.
@misc{RCTS, title = {Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger}, author = {Yang, Qi and Zhang, Chenghao and Fan, Lubin and Ding, Kun and Ye, Jieping and Xiang, Shiming}, year = {2025}, eprint = {2506.07785}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2506.07785}, } -
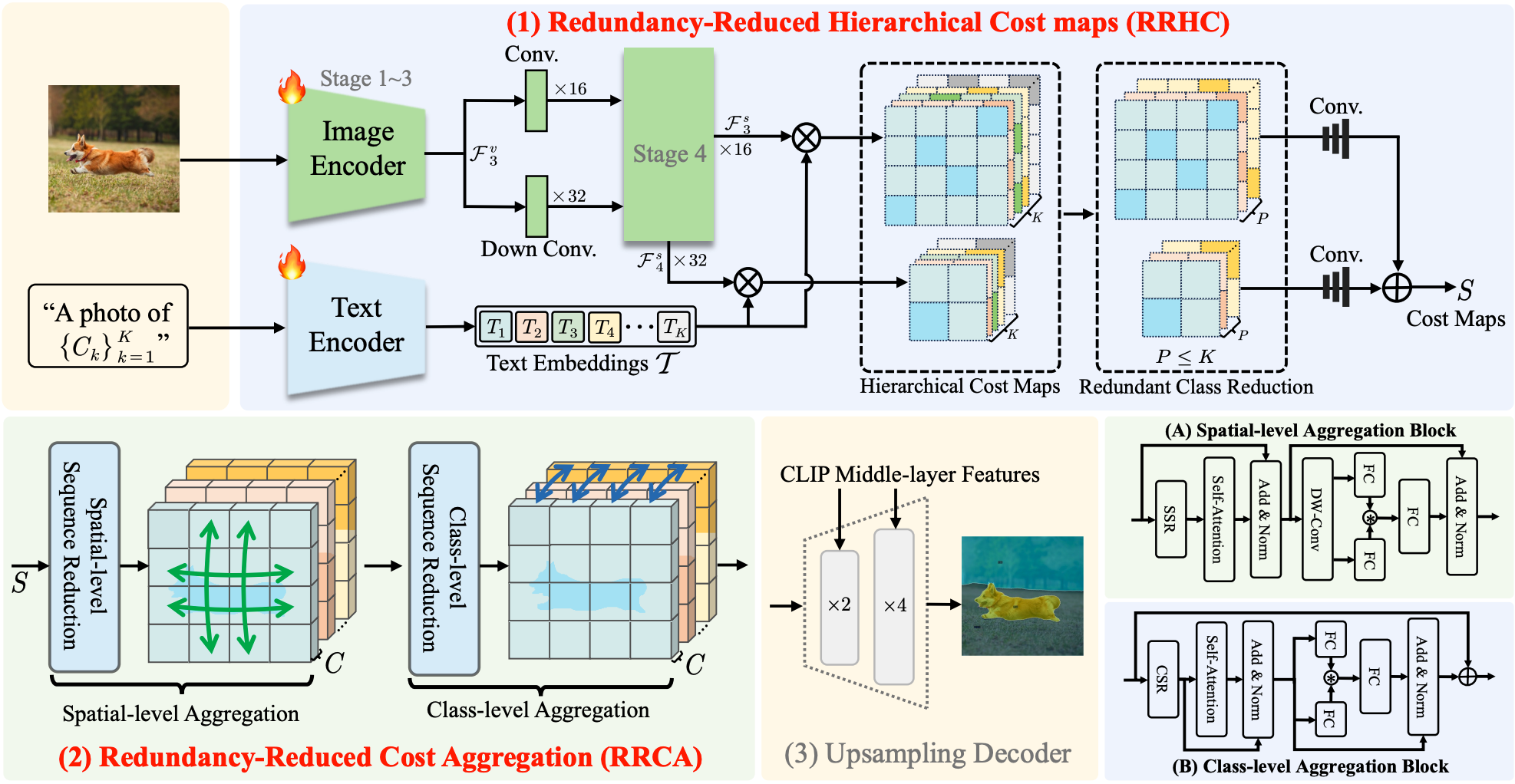 Efficient Redundancy Reduction for Open-Vocabulary Semantic SegmentationNeurocomputing, 2025
Efficient Redundancy Reduction for Open-Vocabulary Semantic SegmentationNeurocomputing, 2025We identify two major sources of redundancy in the cost-based OVSS framework and propose ERR-Seg, an efficient framework that addresses redundant information during cost maps construction and inefficient sequence modeling in cost aggregation. Extensive experiments on multiple benchmarks validate the superiority of ERR-Seg.
@article{ERRSeg, author = {Chen, Lin and Yang, Qi and Ding, Kun and Li, Zhihao and Shen, Gang and Li, Fei and Cao, Qiyuan and Xiang, Shiming}, title = {Efficient Redundancy Reduction for Open-Vocabulary Semantic Segmentation}, journal = {Neurocomputing}, year = {2025}, pages = {132229}, publisher = {Elsevier}, url = {https://www.sciencedirect.com/science/article/pii/S0925231225029017}, } -
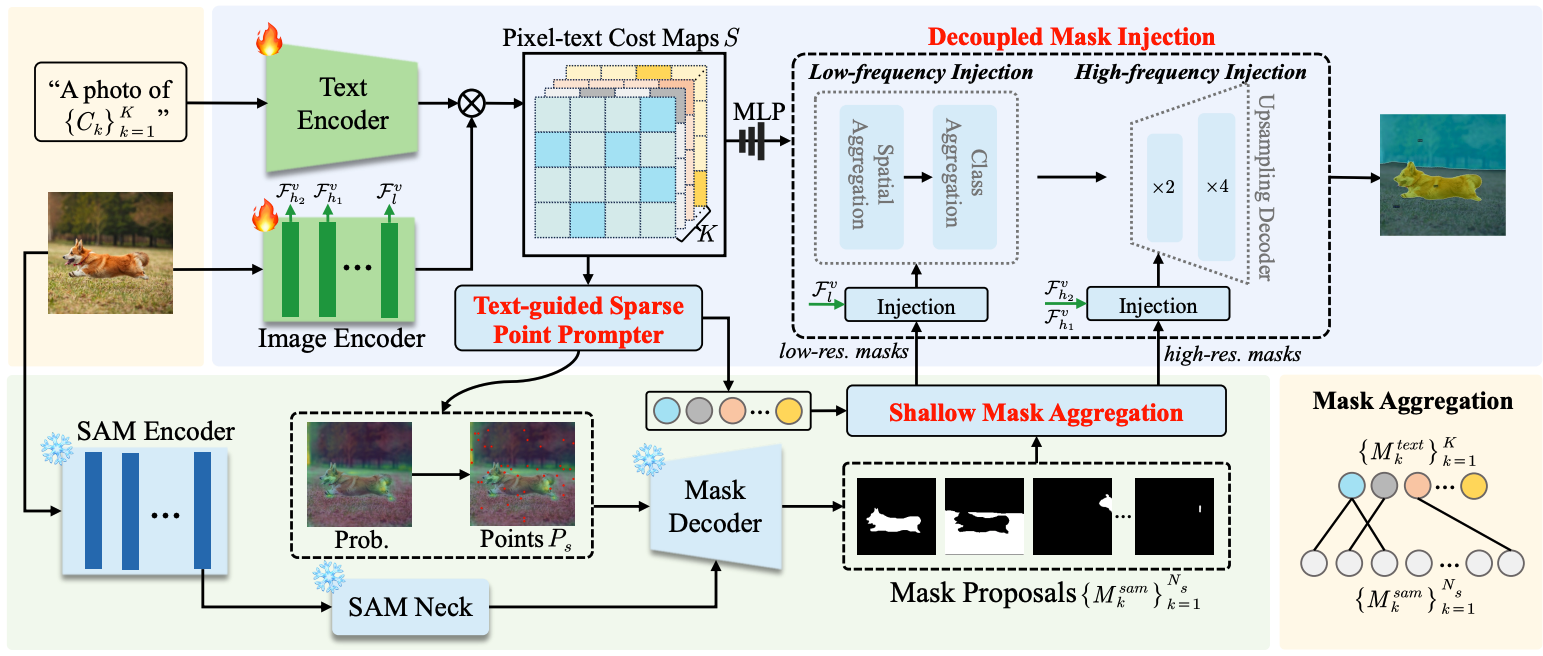 SAM-MI: A Mask-Injected Framework for Enhancing Open-Vocabulary Semantic Segmentation with SAMLin Chen, Yingjian Zhu , Qi Yang, and 3 more authors2025
SAM-MI: A Mask-Injected Framework for Enhancing Open-Vocabulary Semantic Segmentation with SAMLin Chen, Yingjian Zhu , Qi Yang, and 3 more authors2025We introduce SAM-MI, a novel mask-injected framework that effectively integrates SAM with OVSS models. SAM-MI employs a Text-guided Sparse Point Prompter, Shallow Mask Aggregation, and Decoupled Mask Injection. The proposed method achieves a 16.7% relative improvement in mIoU over Grounded-SAM on the MESS benchmark, along with a 1.6x speedup.
@misc{SAMMI, title = {SAM-MI: A Mask-Injected Framework for Enhancing Open-Vocabulary Semantic Segmentation with SAM}, author = {Chen, Lin and Zhu, Yingjian and Yang, Qi and Niu, Xin and Ding, Kun and Xiang, Shiming}, year = {2025}, eprint = {2511.20027}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2511.20027}, } -
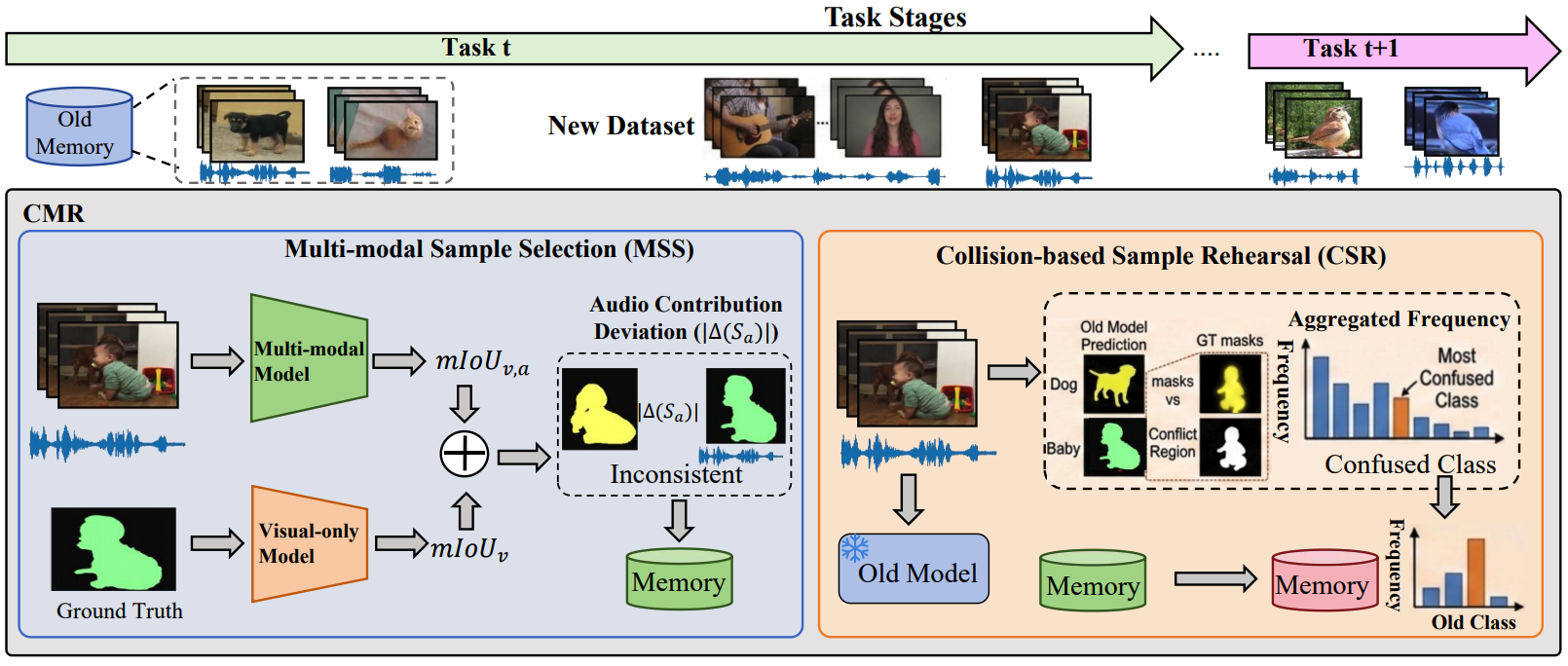 Taming Modality Entanglement in Continual Audio-Visual SegmentationYuyang Hong, Qi Yang, Tao Zhang , and 5 more authors2025
Taming Modality Entanglement in Continual Audio-Visual SegmentationYuyang Hong, Qi Yang, Tao Zhang , and 5 more authors2025We introduce a novel Continual Audio-Visual Segmentation (CAVS) task and design a Collision-based Multi-modal Rehearsal (CMR) framework. We propose Multi-modal Sample Selection (MSS) strategy and Collision-based Sample Rehearsal (CSR) mechanism. Comprehensive experiments demonstrate that our method significantly outperforms single-modal continual learning methods.
@misc{CAVS, title = {Taming Modality Entanglement in Continual Audio-Visual Segmentation}, author = {Hong, Yuyang and Yang, Qi and Zhang, Tao and Wang, Zili and Fu, Zhaojin and Ding, Kun and Fan, Bin and Xiang, Shiming}, year = {2025}, eprint = {2510.17234}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2510.17234}, }







2024
-
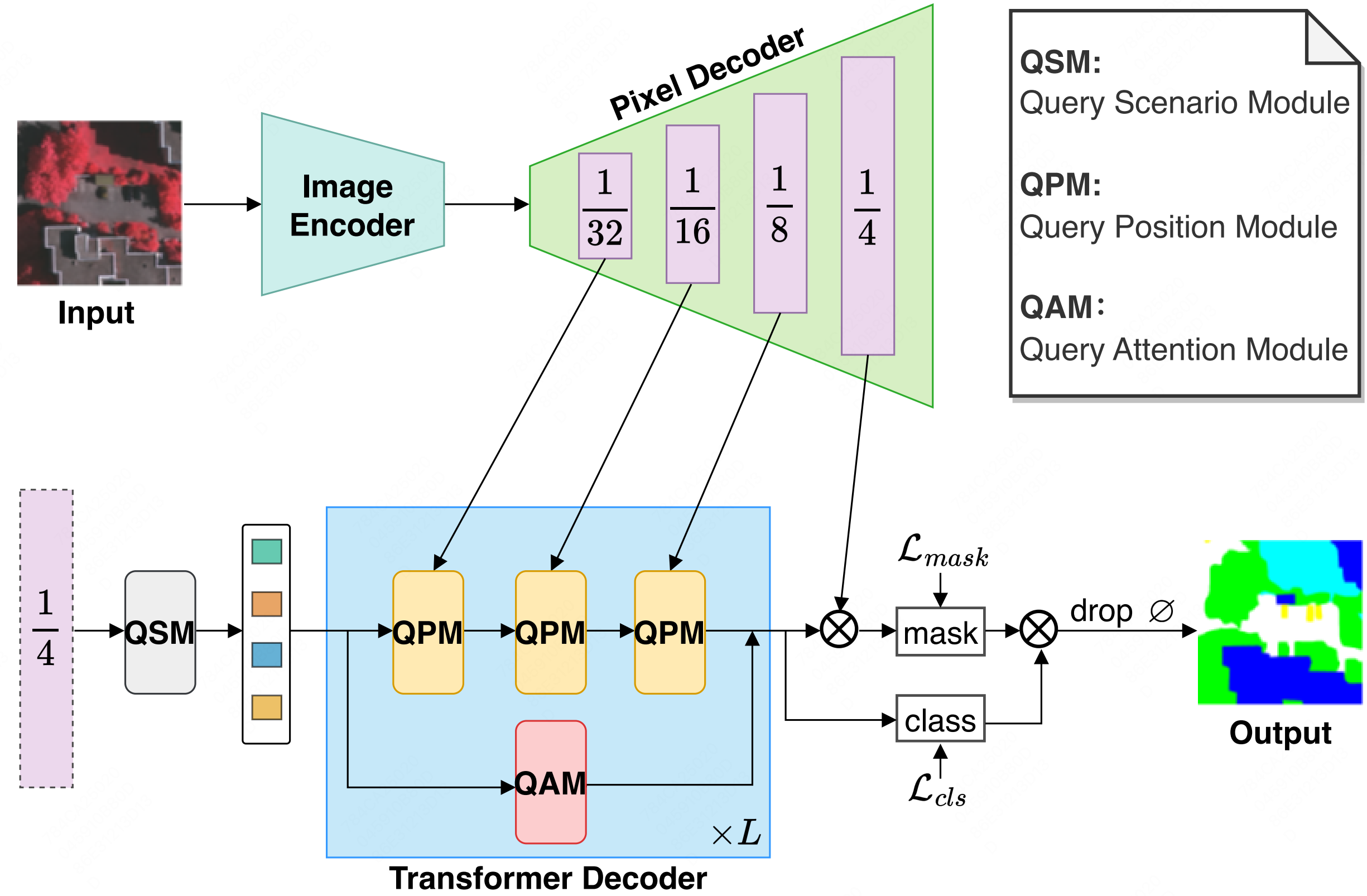 Mask2Former with Improved Query for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang, Shiming Xiang, and 2 more authorsMathematics, 2024
Mask2Former with Improved Query for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang, Shiming Xiang, and 2 more authorsMathematics, 2024Semantic segmentation of remote sensing (RS) images is vital in various practical applications. This paper proposes a Mask2Former with an improved query (IQ2Former) for this task. We propose the Query Scenario Module (QSM), the Query Position Module (QPM), and the Query Attention Module (QAM) to enhance the capability of the query. IQ2Former has demonstrated exceptional performance across three publicly challenging remote-sensing image datasets.
@article{IQ2Former, author = {Guo, Shichen and Yang, Qi and Xiang, Shiming and Wang, Shuwen and Wang, Xuezhi}, title = {Mask2Former with Improved Query for Semantic Segmentation in Remote-Sensing Images}, journal = {Mathematics}, volume = {12}, year = {2024}, number = {5}, article-number = {765}, url = {https://www.mdpi.com/2227-7390/12/5/765}, issn = {2227-7390}, doi = {10.3390/math12050765}, } -
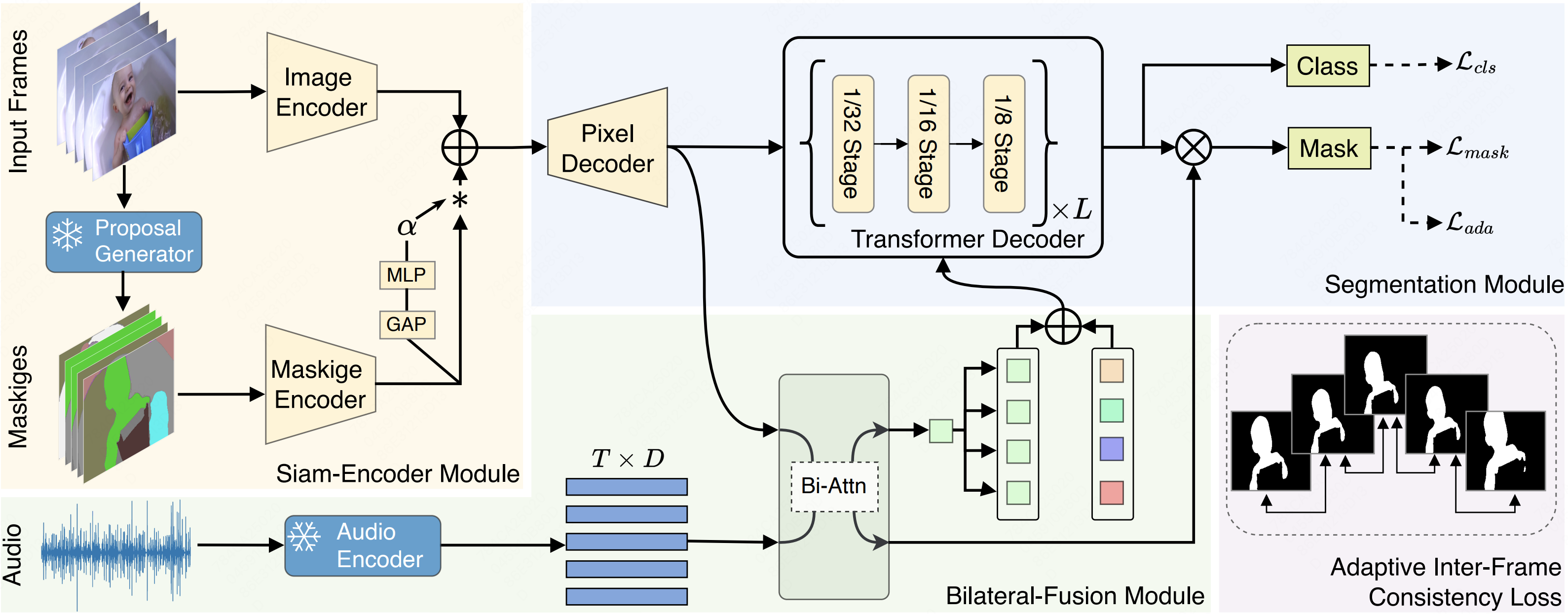 Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual SegmentationIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024CVPR 2024 Highlight
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual SegmentationIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024CVPR 2024 HighlightWe propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Comprehensive experiments on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods.
@inproceedings{COMBO, title = {Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation}, author = {Yang, Qi and Nie, Xing and Li, Tong and Gao, Pengfei and Guo, Ying and Zhen, Cheng and Yan, Pengfei and Xiang, Shiming}, year = {2024}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {27134--27143}, url = {https://arxiv.org/abs/2312.06462}, note = {CVPR 2024 Highlight} } -
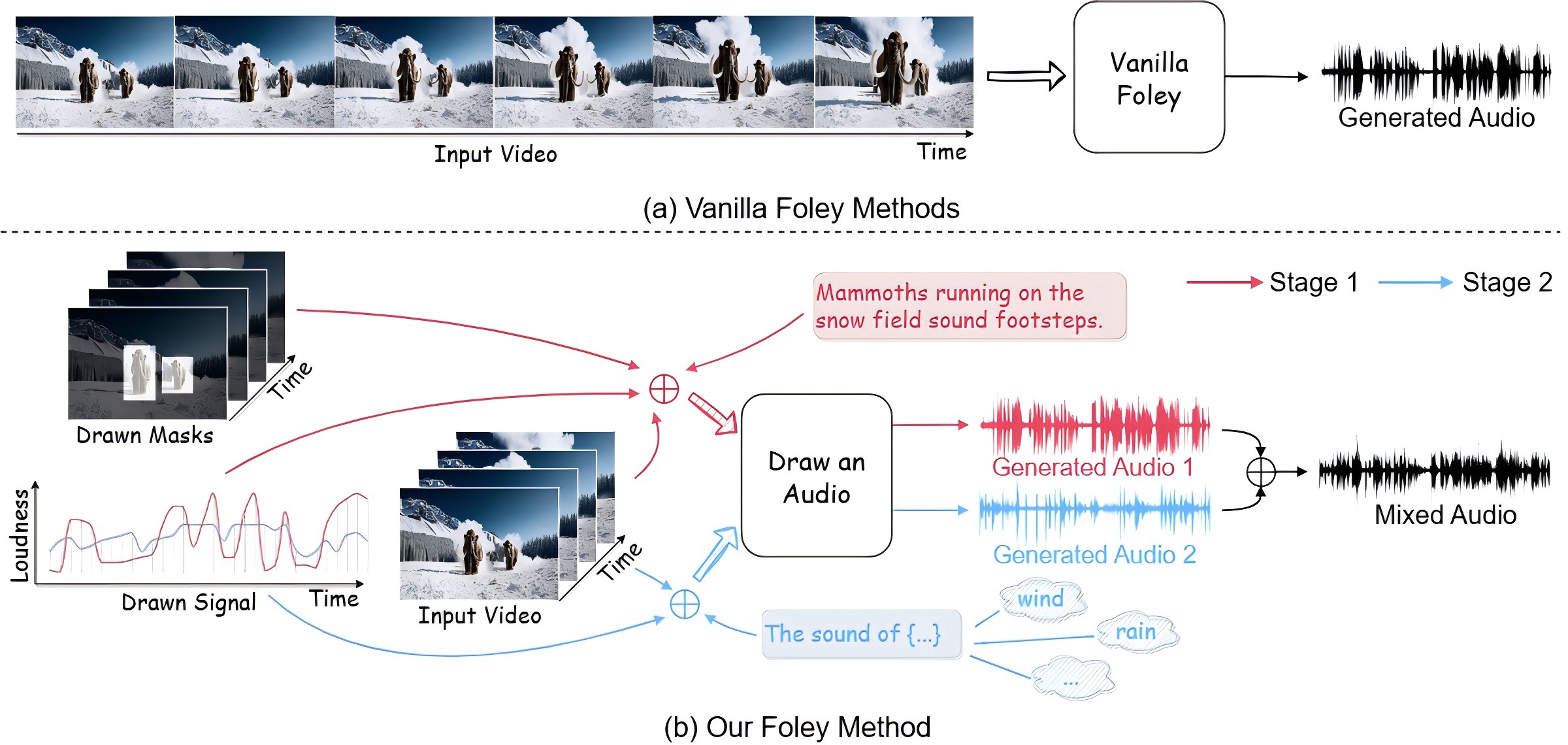 Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio SynthesisQi Yang, Binjie Mao , Zili Wang, and 6 more authors2024
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio SynthesisQi Yang, Binjie Mao , Zili Wang, and 6 more authors2024We construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. We introduce the Mask-Attention Module (MAM) and the Time-Loudness Module (TLM) to ensure content consistency and temporal alignment. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption. Extensive experiments verify Draw an Audio achieves the state-of-the-art.
@misc{DrawAnAudio, title = {Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis}, author = {Yang, Qi and Mao, Binjie and Wang, Zili and Nie, Xing and Gao, Pengfei and Guo, Ying and Zhen, Cheng and Yan, Pengfei and Xiang, Shiming}, year = {2024}, eprint = {2409.06135}, archiveprefix = {arXiv}, primaryclass = {cs.SD}, url = {https://arxiv.org/abs/2409.06135}, } -
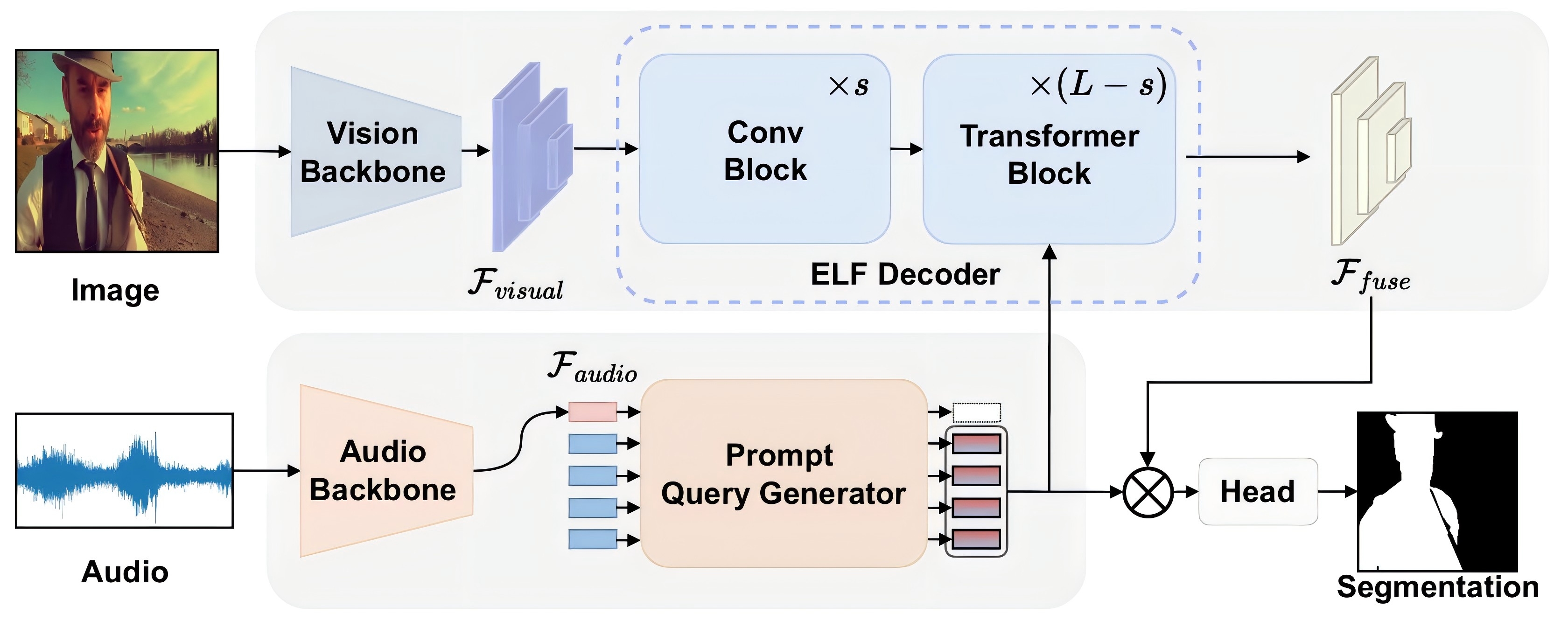 AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual SegmentationZili Wang, Qi Yang, Linsu Shi , and 4 more authors2024
AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual SegmentationZili Wang, Qi Yang, Linsu Shi , and 4 more authors2024We introduce AVESFormer, the first real-time Audio-Visual Efficient Segmentation transformer that achieves fast, efficient and light-weight simultaneously. Our model leverages an efficient prompt query generator to correct the behaviour of cross-attention and proposes ELF decoder to bring greater efficiency. Extensive experiments demonstrate that AVESFormer significantly enhances model performance, achieving 79.9% on S4, 57.9% on MS3 and 31.2% on AVSS.
@misc{AVESFormer, title = {AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual Segmentation}, author = {Wang, Zili and Yang, Qi and Shi, Linsu and Yu, Jiazhong and Liang, Qinghua and Li, Fei and Xiang, Shiming}, year = {2024}, eprint = {2408.01708}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2408.01708}, } -
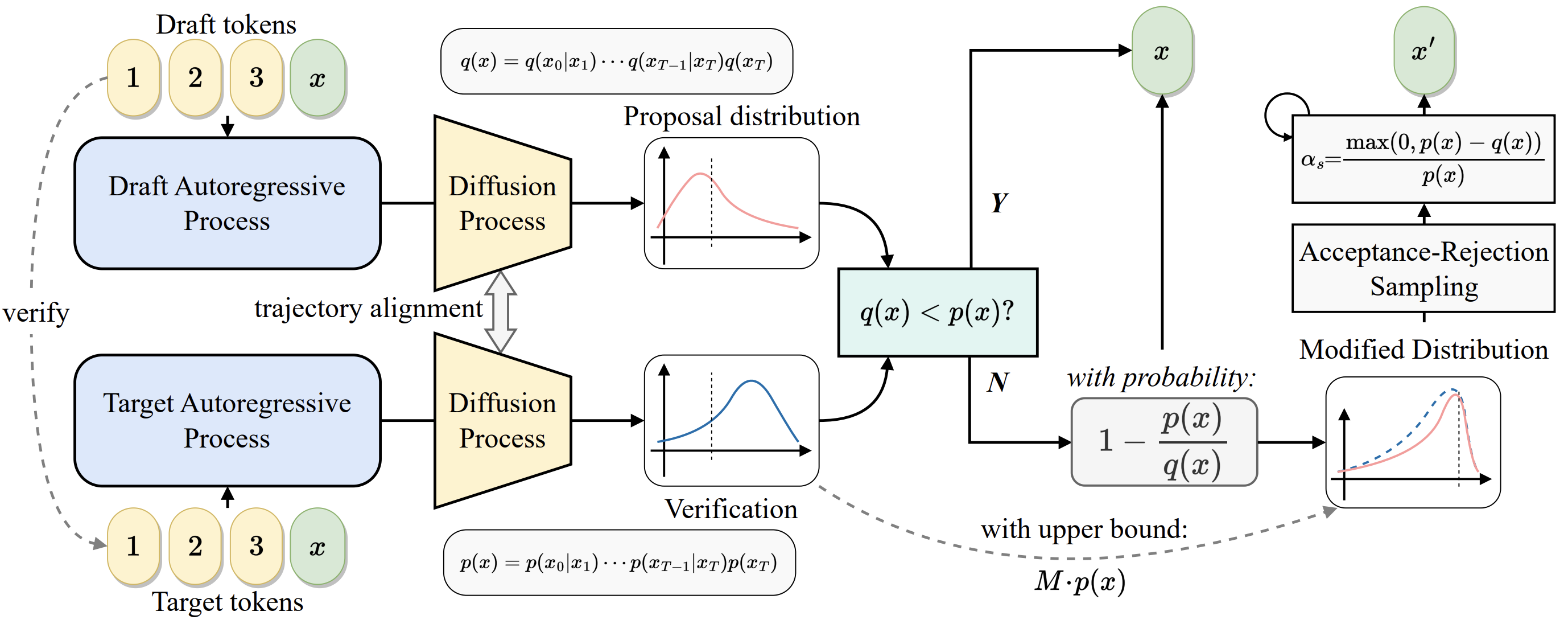 Continuous Speculative Decoding for Autoregressive Image Generation2024
Continuous Speculative Decoding for Autoregressive Image Generation2024This work presents continuous speculative decoding for continuous visual autoregressive models. We propose denoising trajectory alignment, token pre-filling strategies, and an acceptance-rejection sampling algorithm. Extensive experiments demonstrate that our proposed continuous speculative decoding achieves significant speedup on off-the-shelf models while maintaining the original generation quality.
@misc{CSpD, title = {Continuous Speculative Decoding for Autoregressive Image Generation}, author = {Wang, Zili and Zhang, Robert and Ding, Kun and Yang, Qi and Li, Fei and Xiang, Shiming}, year = {2024}, eprint = {2411.11925}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2411.11925}, }





2023
-
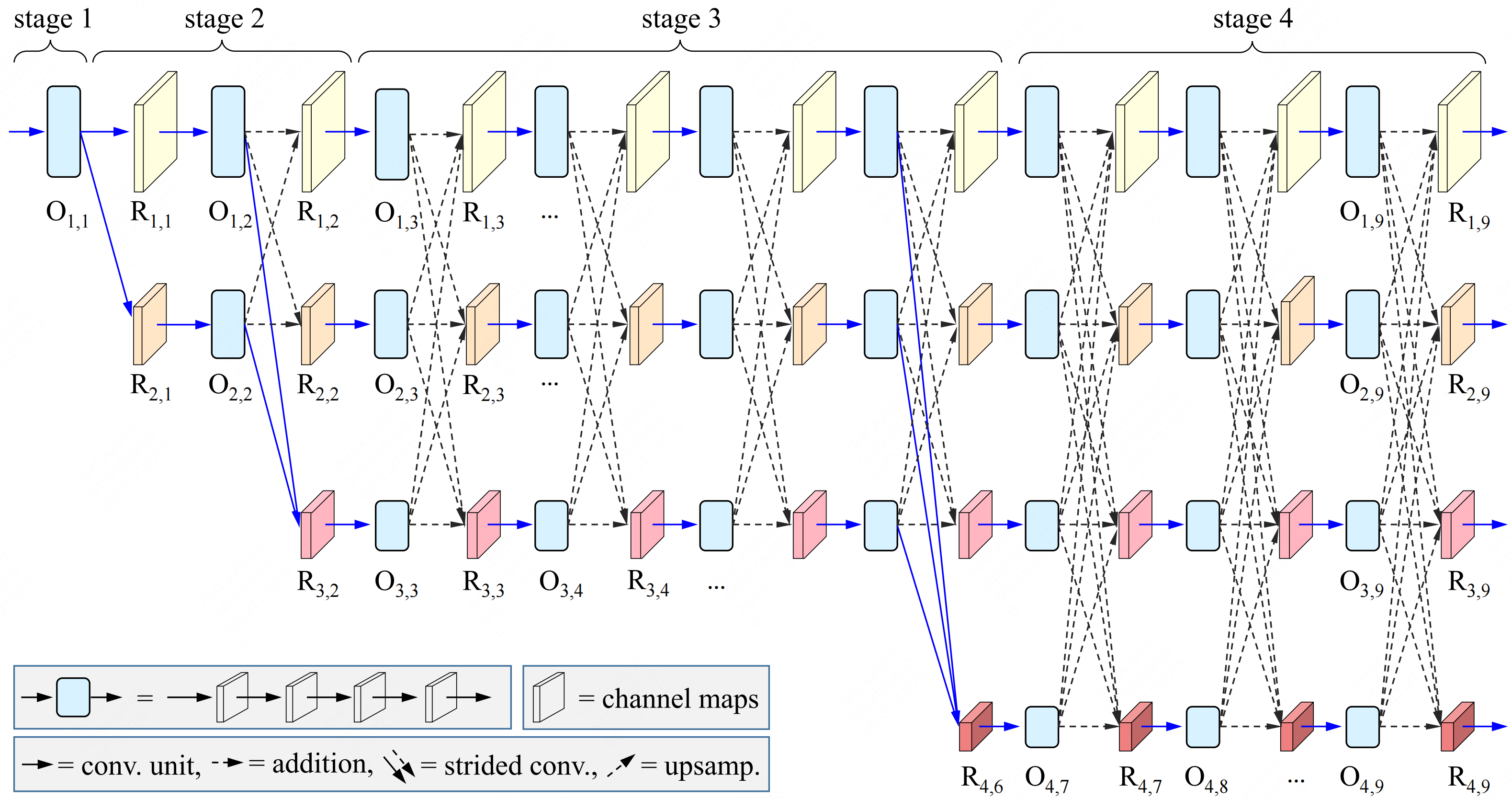 Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang, Shiming Xiang, and 2 more authorsRemote Sensing, 2023
Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang, Shiming Xiang, and 2 more authorsRemote Sensing, 2023Semantic segmentation of remote-sensing (RS) images is one of the most fundamental tasks in the understanding of a remote-sensing scene. This paper proposes a Dynamic High-Resolution Network (DyHRNet) that takes HRNet as a super-architecture, aiming to leverage the important connections and channels by further investigating the parallel streams at different resolution representations. The learning task is conducted under the framework of a neural architecture search (NAS) and channel-wise attention module. DyHRNet has shown high performance on three public challenging RS image datasets (Vaihingen, Potsdam, and LoveDA).
@article{DyHRNet, author = {Guo, Shichen and Yang, Qi and Xiang, Shiming and Wang, Pengfei and Wang, Xuezhi}, title = {Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing Images}, journal = {Remote Sensing}, volume = {15}, year = {2023}, number = {9}, article-number = {2293}, url = {https://www.mdpi.com/2072-4292/15/9/2293}, issn = {2072-4292}, doi = {10.3390/rs15092293}, keywords = {semantic segmentation;remote-sensing image;neural architecture search;sparse regularization;HRNet}, } -
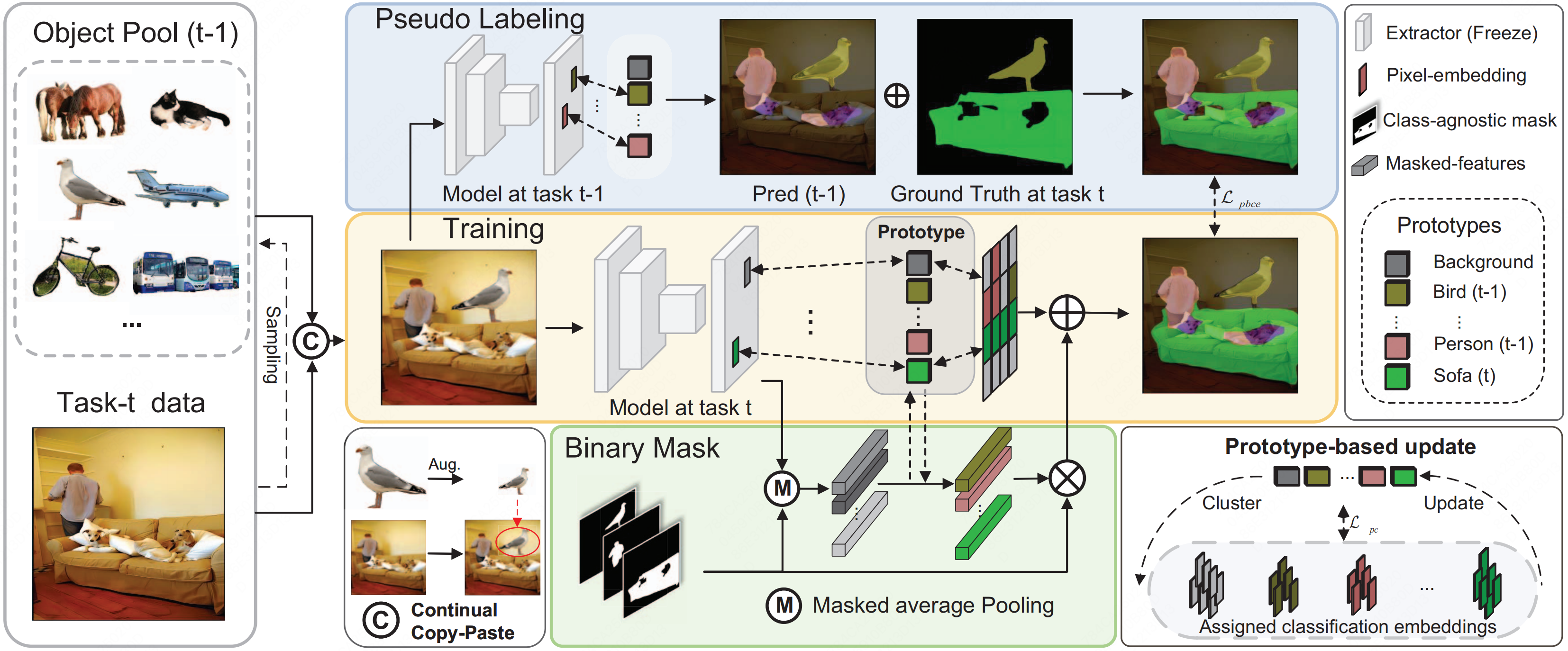 Continual Semantic Segmentation via Scalable Contrastive Clustering and Background DiversityQi Yang, Xing Nie, Linsu Shi , and 3 more authorsIn 2023 IEEE International Conference on Data Mining (ICDM) , 2023
Continual Semantic Segmentation via Scalable Contrastive Clustering and Background DiversityQi Yang, Xing Nie, Linsu Shi , and 3 more authorsIn 2023 IEEE International Conference on Data Mining (ICDM) , 2023Despite the efficacy towards static data distribution, traditional semantic segmentation methods encounter Catastrophic forgetting when tackling continually changing data streams. We introduce a novel, scalable segmentation architecture called ScaleSeg, designed to adapt the incremental scenarios. The architecture consists of a series of prototypes updated by online contrastive clustering. Additionally, we propose a background diversity strategy to enhance the model’s plasticity and stability, thus overcoming background shift. Comprehensive experiments demonstrate that ScaleSeg surpasses previous state-of-the-art methods.
@inproceedings{ScaleSeg, author = {Yang, Qi and Nie, Xing and Shi, Linsu and Yu, Jiazhong and Li, Fei and Xiang, Shiming}, booktitle = {2023 IEEE International Conference on Data Mining (ICDM)}, title = {Continual Semantic Segmentation via Scalable Contrastive Clustering and Background Diversity}, year = {2023}, pages = {1475-1480}, url = {https://ieeexplore.ieee.org/document/10415751}, doi = {10.1109/ICDM58522.2023.00194}, issn = {2374-8486} }

