publications
Happy to be cited!
2024
-
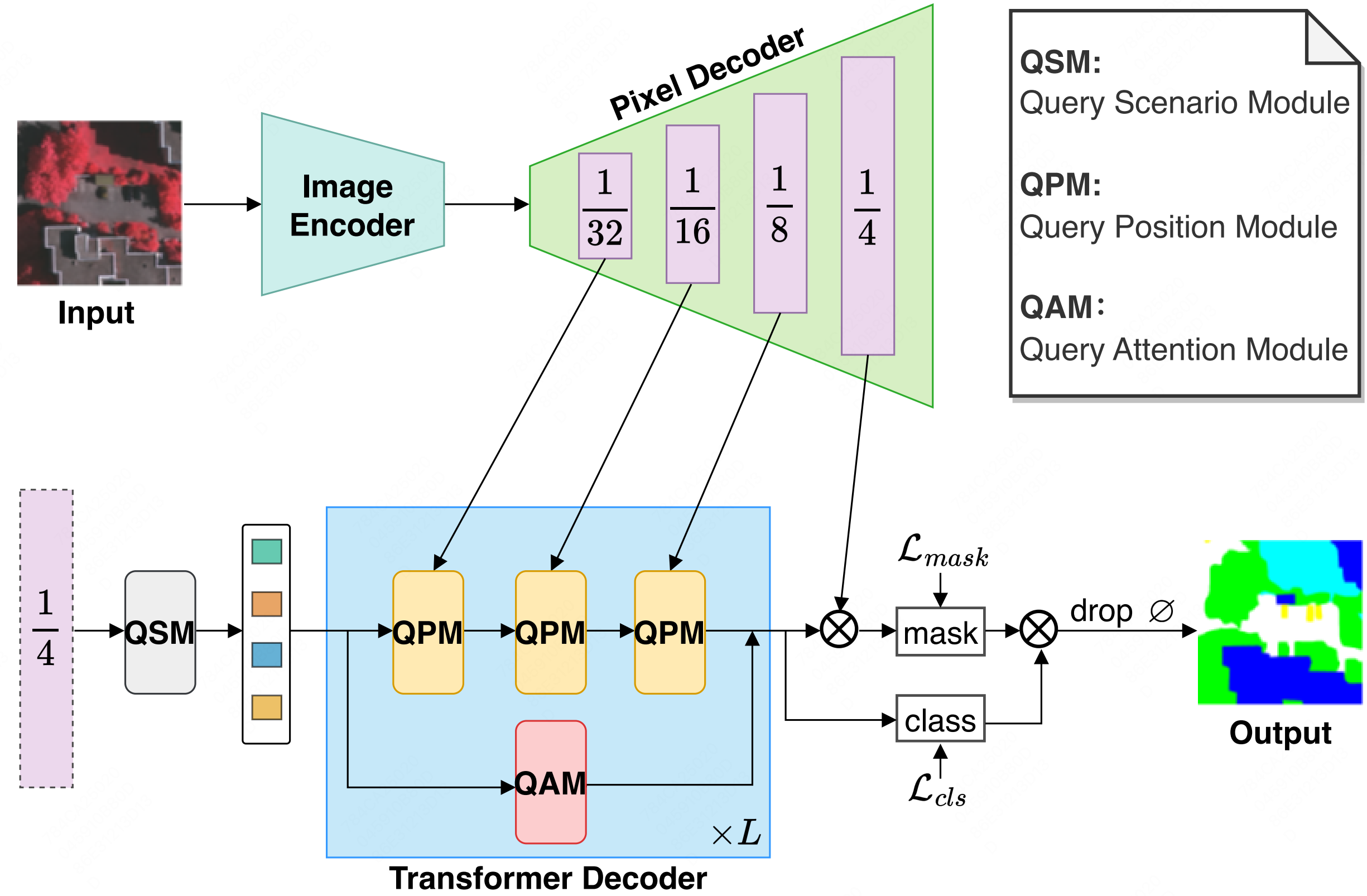 Mask2Former with Improved Query for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang , Shiming Xiang , and 2 more authorsMathematics, 2024
Mask2Former with Improved Query for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang , Shiming Xiang , and 2 more authorsMathematics, 2024Semantic segmentation of remote sensing (RS) images is vital in various practical applications, including urban construction planning, natural disaster monitoring, and land resources investigation. However, RS images are captured by airplanes or satellites at high altitudes and long distances, resulting in ground objects of the same category being scattered in various corners of the image. Moreover, objects of different sizes appear simultaneously in RS images. For example, some objects occupy a large area in urban scenes, while others only have small regions. Technically, the above two universal situations pose significant challenges to the segmentation with a high quality for RS images. Based on these observations, this paper proposes a Mask2Former with an improved query (IQ2Former) for this task. The fundamental motivation behind the IQ2Former is to enhance the capability of the query of Mask2Former by exploiting the characteristics of RS images well. First, we propose the Query Scenario Module (QSM), which aims to learn and group the queries from feature maps, allowing the selection of distinct scenarios such as the urban and rural areas, building clusters, and parking lots. Second, we design the query position module (QPM), which is developed to assign the image position information to each query without increasing the number of parameters, thereby enhancing the model’s sensitivity to small targets in complex scenarios. Finally, we propose the query attention module (QAM), which is constructed to leverage the characteristics of query attention to extract valuable features from the preceding queries. Being positioned between the duplicated transformer decoder layers, QAM ensures the comprehensive utilization of the supervisory information and the exploitation of those fine-grained details. Architecturally, the QSM, QPM, and QAM as well as an end-to-end model are assembled to achieve high-quality semantic segmentation. In comparison to the classical or state-of-the-art models (FCN, PSPNet, DeepLabV3+, OCRNet, UPerNet, MaskFormer, Mask2Former), IQ2Former has demonstrated exceptional performance across three publicly challenging remote-sensing image datasets, 83.59 mIoU on the Vaihingen dataset, 87.89 mIoU on Potsdam dataset, and 56.31 mIoU on LoveDA dataset. Additionally, overall accuracy, ablation experiment, and visualization segmentation results all indicate IQ2Former validity.
-
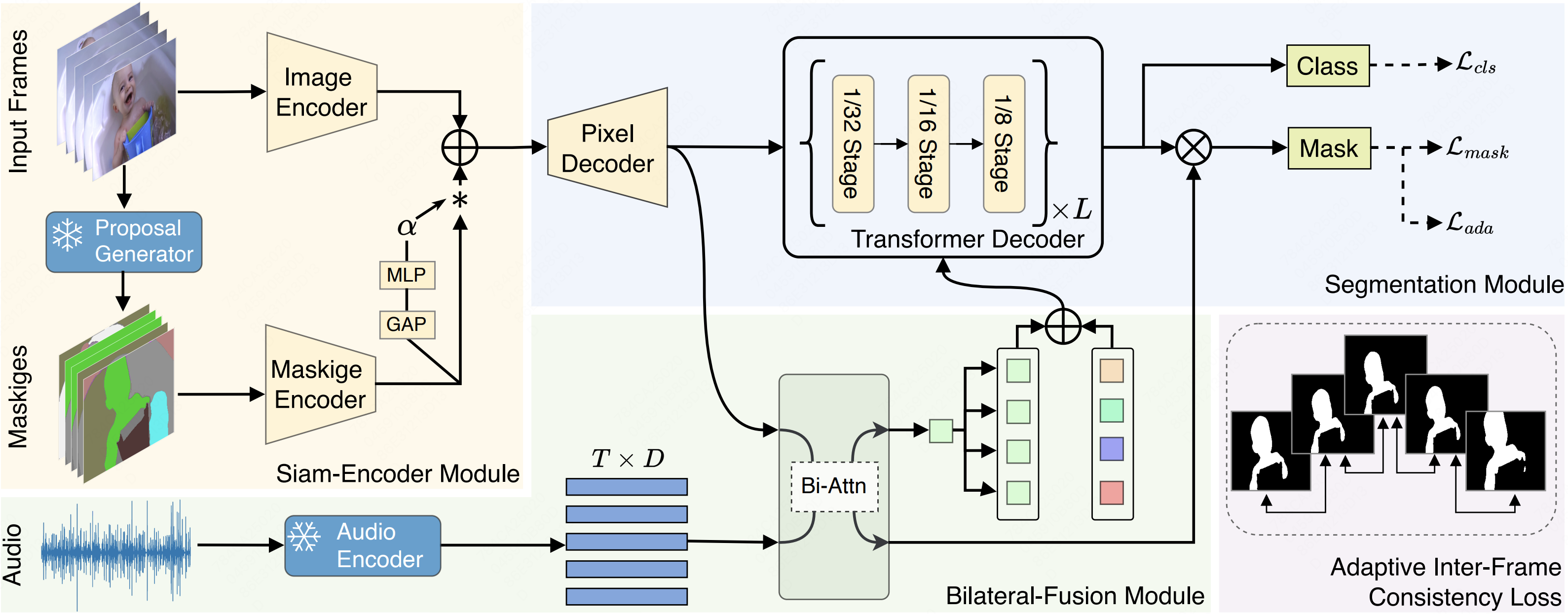 Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual SegmentationQi Yang , Xing Nie , Tong Li , and 5 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual SegmentationQi Yang , Xing Nie , Tong Li , and 5 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods.
-
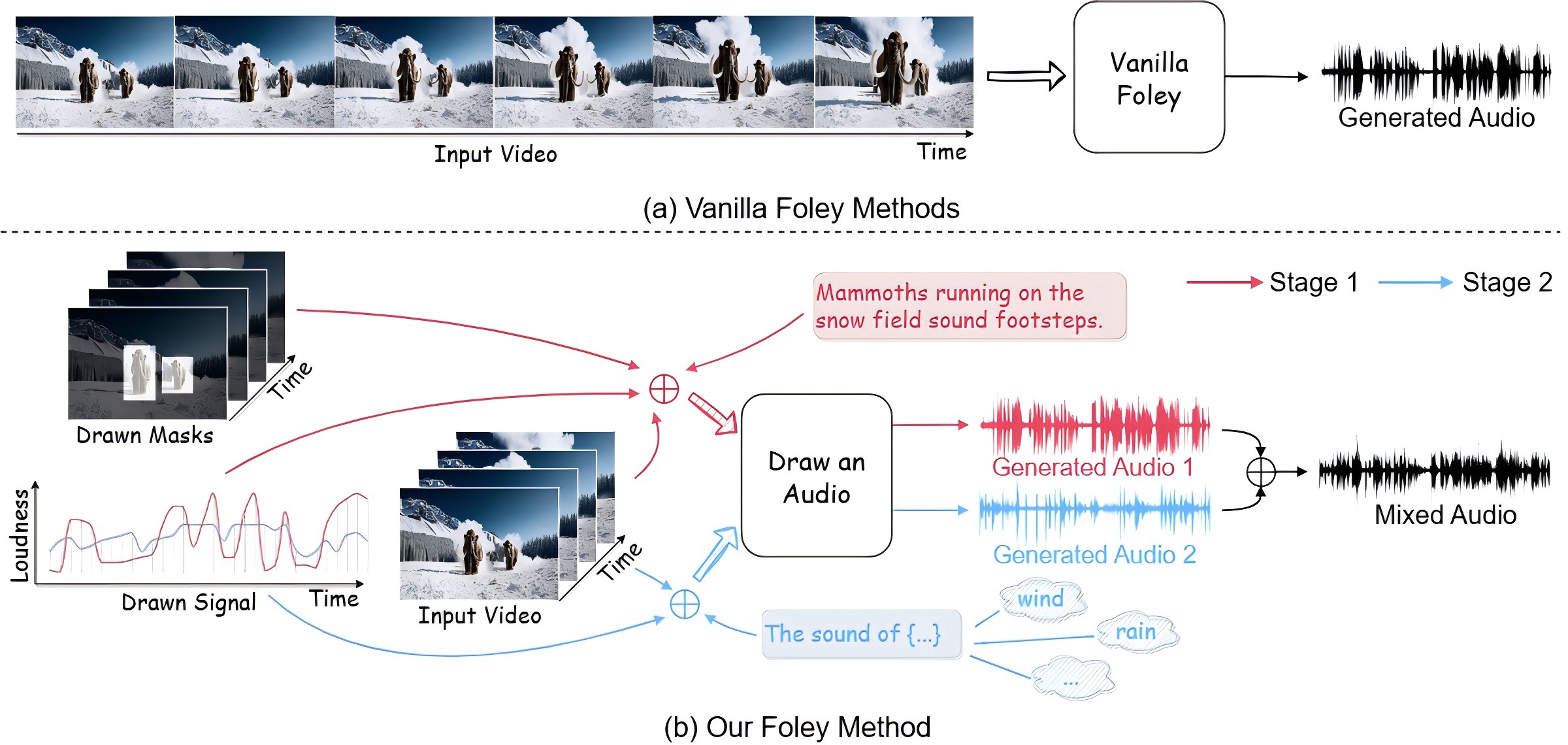 Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio SynthesisQi Yang , Binjie Mao , Zili Wang , and 6 more authors2024
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio SynthesisQi Yang , Binjie Mao , Zili Wang , and 6 more authors2024Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art.
-
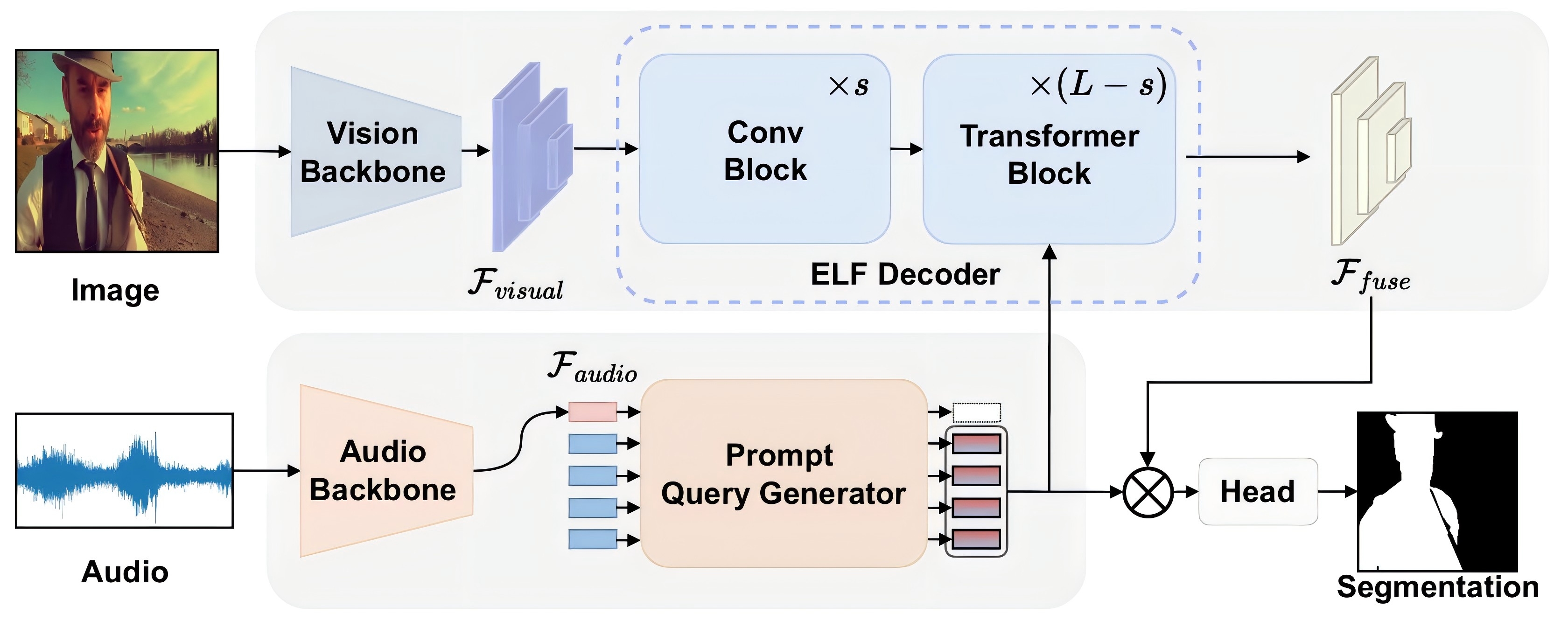 AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual SegmentationZili Wang , Qi Yang , Linsu Shi , and 4 more authors2024
AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual SegmentationZili Wang , Qi Yang , Linsu Shi , and 4 more authors2024Recently, transformer-based models have demonstrated remarkable performance on audio-visual segmentation (AVS) tasks. However, their expensive computational cost makes real-time inference impractical. By characterizing attention maps of the network, we identify two key obstacles in AVS models: 1) attention dissipation, corresponding to the over-concentrated attention weights by Softmax within restricted frames, and 2) inefficient, burdensome transformer decoder, caused by narrow focus patterns in early stages. In this paper, we introduce AVESFormer, the first real-time Audio-Visual Efficient Segmentation transformer that achieves fast, efficient and light-weight simultaneously. Our model leverages an efficient prompt query generator to correct the behaviour of cross-attention. Additionally, we propose ELF decoder to bring greater efficiency by facilitating convolutions suitable for local features to reduce computational burdens. Extensive experiments demonstrate that our AVESFormer significantly enhances model performance, achieving 79.9% on S4, 57.9% on MS3 and 31.2% on AVSS, outperforming previous state-of-the-art and achieving an excellent trade-off between performance and speed.




2023
-
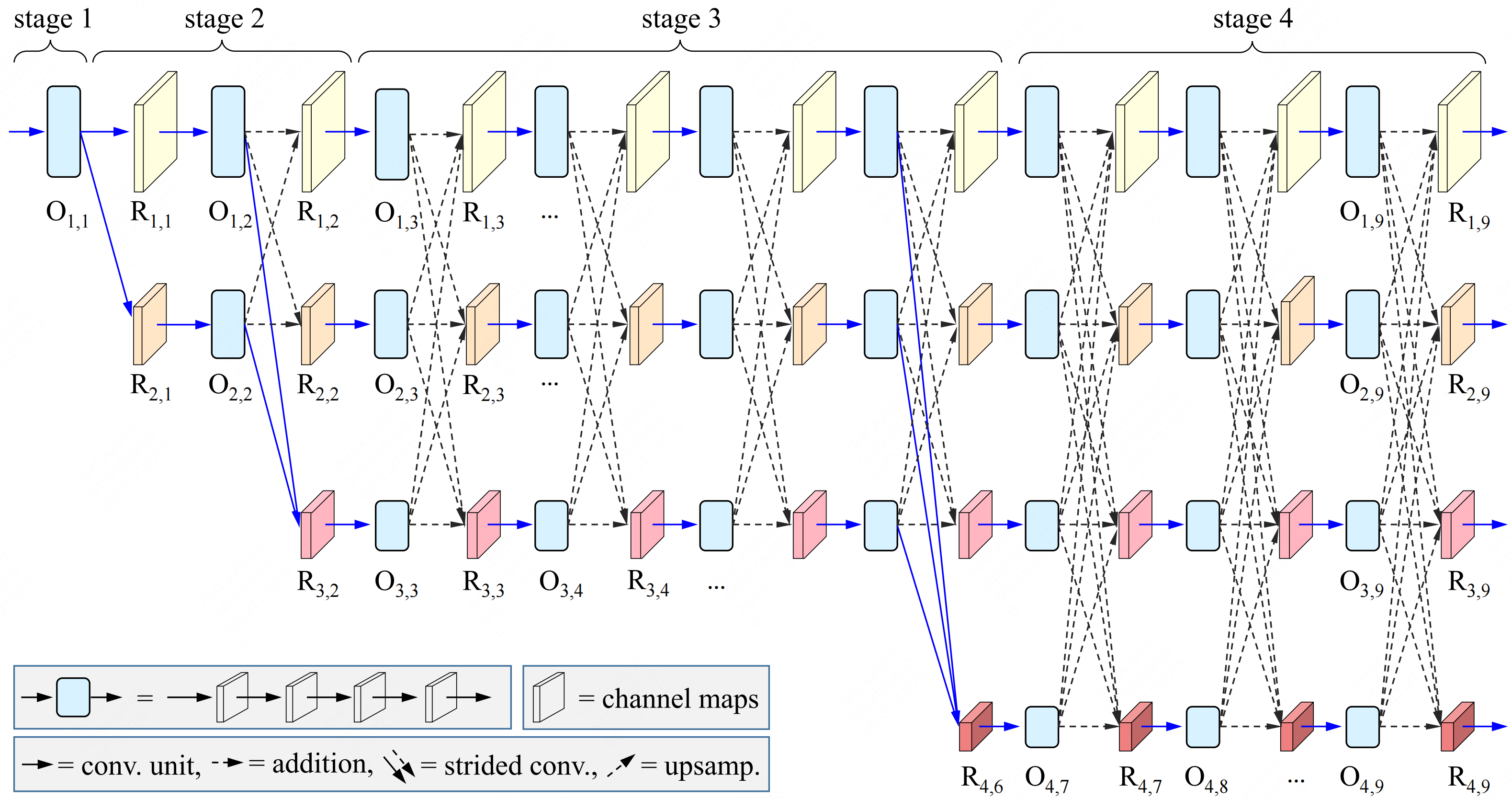 Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang , Shiming Xiang , and 2 more authorsRemote Sensing, 2023
Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing ImagesShichen Guo , Qi Yang , Shiming Xiang , and 2 more authorsRemote Sensing, 2023Semantic segmentation of remote-sensing (RS) images is one of the most fundamental tasks in the understanding of a remote-sensing scene. However, high-resolution RS images contain plentiful detailed information about ground objects, which scatter everywhere spatially and have variable sizes, styles, and visual appearances. Due to the high similarity between classes and diversity within classes, it is challenging to obtain satisfactory and accurate semantic segmentation results. This paper proposes a Dynamic High-Resolution Network (DyHRNet) to solve this problem. Our proposed network takes HRNet as a super-architecture, aiming to leverage the important connections and channels by further investigating the parallel streams at different resolution representations of the original HRNet. The learning task is conducted under the framework of a neural architecture search (NAS) and channel-wise attention module. Specifically, the Accelerated Proximal Gradient (APG) algorithm is introduced to iteratively solve the sparse regularization subproblem from the perspective of neural architecture search. In this way, valuable connections are selected for cross-resolution feature fusion. In addition, a channel-wise attention module is designed to weight the channel contributions for feature aggregation. Finally, DyHRNet fully realizes the dynamic advantages of data adaptability by combining the APG algorithm and channel-wise attention module simultaneously. Compared with nine classical or state-of-the-art models (FCN, UNet, PSPNet, DeepLabV3+, OCRNet, SETR, SegFormer, HRNet+FCN, and HRNet+OCR), DyHRNet has shown high performance on three public challenging RS image datasets (Vaihingen, Potsdam, and LoveDA). Furthermore, the visual segmentation results, the learned structures, the iteration process analysis, and the ablation study all demonstrate the effectiveness of our proposed model.
-
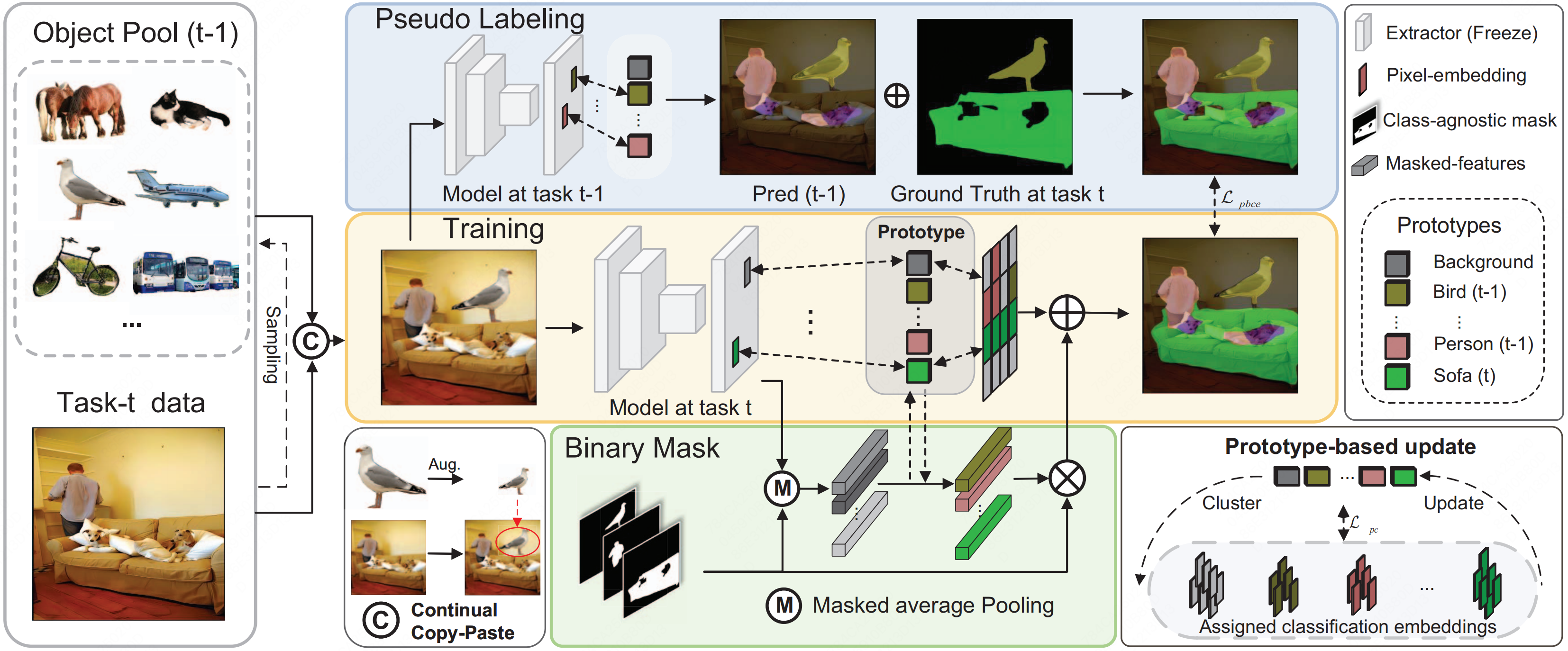 Continual Semantic Segmentation via Scalable Contrastive Clustering and Background DiversityQi Yang , Xing Nie , Linsu Shi , and 3 more authorsIn 2023 IEEE International Conference on Data Mining (ICDM) , 2023
Continual Semantic Segmentation via Scalable Contrastive Clustering and Background DiversityQi Yang , Xing Nie , Linsu Shi , and 3 more authorsIn 2023 IEEE International Conference on Data Mining (ICDM) , 2023Despite the efficacy towards static data distribution, traditional semantic segmentation methods encounter Catastrophic forgetting when tackling continually changing data streams. Another fundamental challenge is Background shift, which results from the semantic drift of the background class during continual learning steps. To extend the applicability of semantic segmentation methods, we introduce a novel, scalable segmentation architecture called ScaleSeg, designed to adapt the incremental scenarios. The architecture of ScaleSeg consists of a series of prototypes updated by online contrastive clustering. Additionally, we propose a background diversity strategy to enhance the model’s plasticity and stability, thus overcoming background shift. Comprehensive experiments and ablation studies on challenging benchmarks demonstrate that ScaleSeg surpasses previous state-of-the-art methods, particularly when dealing with extensive task sequences.

